
軽量・高機能・
安心サポートで、
ジョブ管理を進化させる
Job Arranger(ジョブアレンジャー)は、大和総研が提供するジョブ管理ツールです。
統合監視ツール「Zabbix」のアドオンとして利用できます。


※2012年12月〜2025年4月現在の全バージョン累計ダウンロード数

Zabbixにアドオンして利用する
OSSのジョブ管理ツール
Job Arrangerは、大和総研が提供するOSS(オープンソースソフトウェア)のジョブ管理ツールです。統合監視ツール「Zabbix」のアドオンとして利用できます。
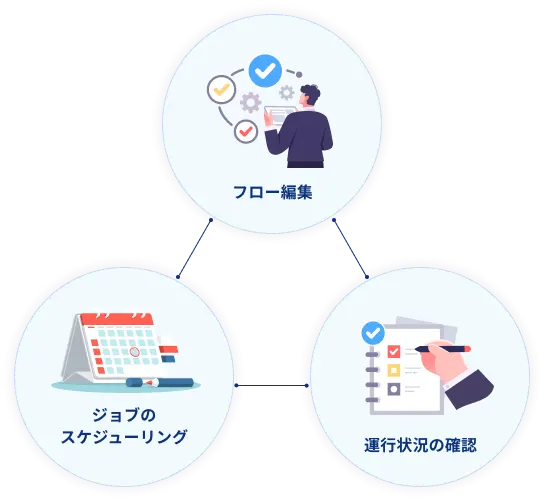
本ツールのダウンロード・利用は無料です。ジョブのスケジューリング、フロー編集、運行状況の確認など、多機能なジョブ管理を実現します。
官公庁、金融機関、通信業界などさまざまなお客様にご利用いただき、ミッションクリティカルなシステムでも導入実績があります。
大和総研はそのノウハウを活かして構築・活用の支援を行っています。
 4つの特長
4つの特長
直感的な操作で、
複雑なジョブ管理も簡単に実現
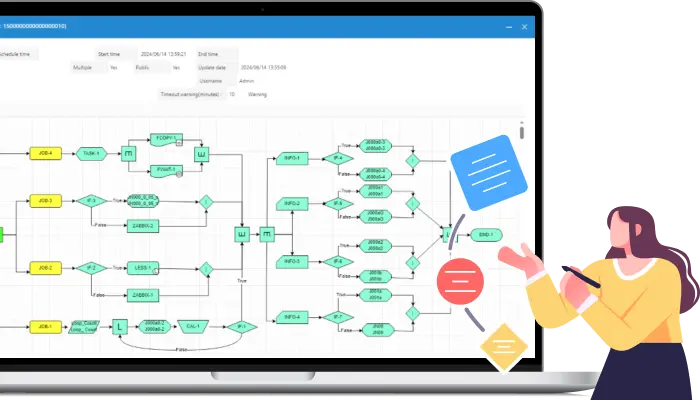
- マウス操作で直感的にフローチャートを作成。
複雑なジョブフローもカンタンに管理可能です。 - 1年分のカレンダーを一画面で表示。
稼働日がひと目で把握できます。 - カレンダーの編集で、稼働日のオンオフやジョブネットのスケジュール調整もスムーズに行えます。
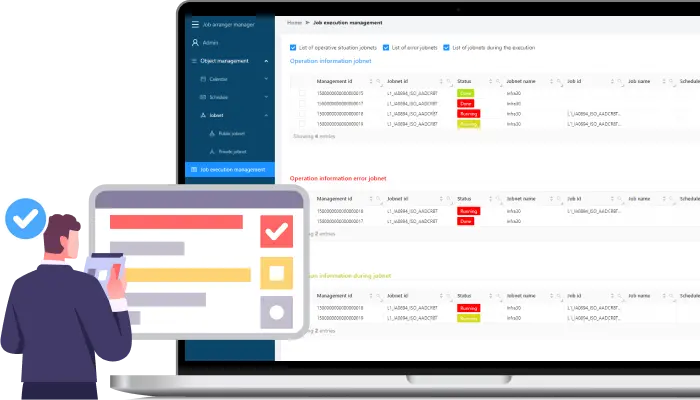

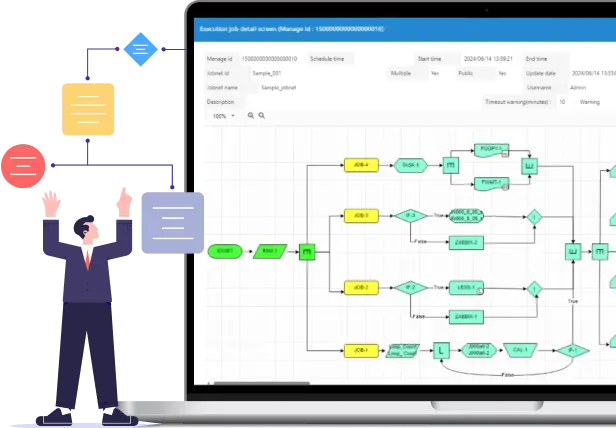
運行状況を一元管理
ジョブネットの実行予定・稼働状況を一つの画面で確認できます。
さらに、さらに、ジョブネットの状況をリアルタイムに確認し、保留や強制停止などの操作を行えます。


Zabbixや外部アプリケーションと
容易に連携
Zabbixにアドオンして利用するツールのため、Zabbixとのシームレスな連携が可能です。
また、Job Arrangerのジョブ管理機能を外部から操作するためのインターフェースが用意されており、Redmineなど他のアプリケーションからもカンタンに連携できます。


万全のサポート体制
Job Arrangerは、OSS(オープンソースソフトウェア)として無料でお使いいただけますが、エンタープライズ向けの利用でも安心してお使いいただけるよう、大和総研が有償のサポートサービスをご提供しています。

軽量・高機能・安心サポートで、ジョブ管理を進化させる
大和総研の
サポートサービスのご案内

 柔軟にサポート対象を選択
柔軟にサポート対象を選択
導入や保守、Zabbixのみ・Job Arrangerのみ、ZabbixとJobArrangerの両方など、サービス内容を最適化できます。
また、コミュニティサイトも備えており、豊富なナレッジを参照しながら導入、運用が可能です。


 大和総研の実績とノウハウ
大和総研の実績とノウハウ
大和総研は、大和証券グループをはじめとする金融系お客様のミッションクリティカルなシステムをご提供し続けています。その実績とノウハウを活かし、高いサポート品質で、安心をご提供いたします。



